| Field signal | Workflow condition | Maintained artefact |
|---|---|---|
| Procedure skills | procedure | authored task files and local operating rules |
| Attribution substrate | source attachment | extraction pipelines with source locations |
| Source interfaces | source access | approved source sets and served representations |
| File-backed state | continuity | context files, decisions, open questions, and history |
| Harness engineering | control | execution, validation, permissions, and stopping rules |
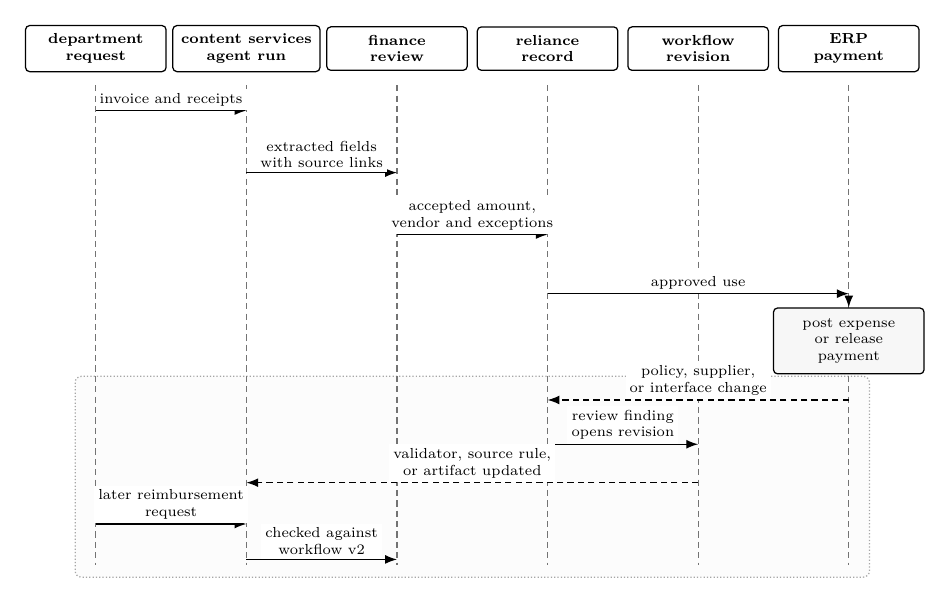
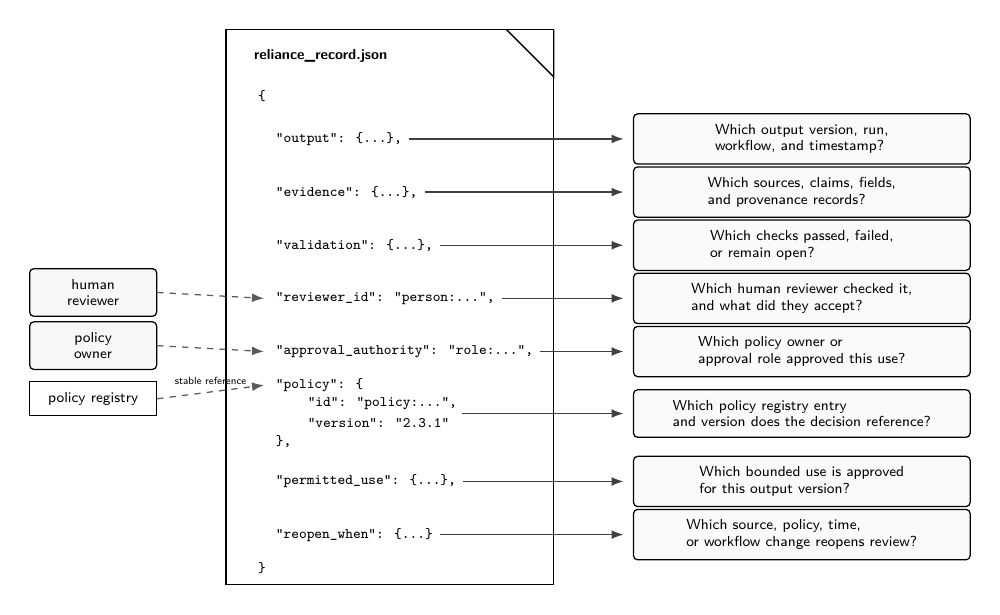
| Reliance layer | institutional use | TBD |