The Regulatory Problem
Mapping source authority onto product architecture is the central problem in regulatory requirements work.
The regulation and the architecture describe the same future system from different directions. The regulation describes the allowed system (actors, records, obligations, time limits, control powers, evidence expectations etc), while the product architecture describes the running system (components, data flows, failure modes, ownership boundaries, support processes, customer-facing claims etc). Requirements are actionable only after those two descriptions are joined into one product model.
Time adds another distinction. Each statement may become stale as often as the regulator revisits their requirements. A flat Confluence page can hold that status, but only when the team enforces it manually, the source otherwise loses track of why it holds the requirement and when it should be reviewed.
These problems meet at in product management praxis, where conceptual classification becomes operating work and needs to inform project planning, stakeholder advisory, externally facing comms and so forth. Such challenges may also be understood as a knowledge representation problem. A successful representation of a highly regulated product has to bind authoritative sources, requirements interpretations, delivery state, communication boundaries, and temporal logic into the same maintained object, so that teams can reason over versions, dependencies, approvals, and permissible claims.
This article is a review of my experience working as a Product Manager in the software fiscalisation domain. It summarises my attempts at the conceptual and pragmatic tasks I described above, and a few of the challenges I encountered throughout.
A Software Fiscal Machine
The job of fiscalisation software is to turn a retail sale into a fiscal record. The system records the operation, preserves the required data in a verifiable form, issues the commercial document and sends the daily receipt data to the authority.1 That work makes the software a regulated fiscal component with duties exceeding ordinary point-of-sale features. For products sold across European fiscalisation regimes, the recurring duties are durable fiscal records, attributable submissions, tamper-evident data, regulated transmission, inspection access and so forth.2
The Italian case is particularly interesting when it comes to requirements elicitation and maintenance. At the time my team tackled it, software fiscalisation in Italy had only recently been authorised3, which made it a disruptive change in an industry previously dominated by hardware-only compliance. In that still-unsettled territory, the institutional technical specifications that would guide implementation moved on their own difficult timeline4, with shifts in versions, phrasing, and interpretation. Apart from direct governmental channels, the team had to incorporate and triage information from stakeholder roundtables, category-association conferences, meetings with industry actors, including both written materials and oral clarifications, across formal and informal settings with different degrees of authority.
For all these reasons, the team had few priors for mapping the fiscal functions onto the target product, which made requirements unstable where source terms still had to be translated into architecture, ownership, evidence and support obligations.
Regulatory Distillation
What we may call regulatory distillation is the conversion of a regulatory and institutional corpus into accepted product state. The first finding, as I have already hinted, is that the corpus contains several source classes. Official specifications, annexes, institutional clarifications, internal architecture knowledge, questions from customers or partners and miscellaneous intel can all trigger new product work, but each statement needs its authority class and version before it enters the requirement model.
The second finding is that distillation works as a pipeline. Source material enters with authority class and version. Terms are normalised into a practical domain model of actors, components, fiscal objects and relations. Requirement-bearing statements then receive provenance state and product state. Provenance state records where the statement comes from and when it needs review, while product state records where it lands in the architecture and what work it creates. The resulting record must be then evaluated against the target architecture before it is projected into dedicated engineering, sales, support or leadership views.
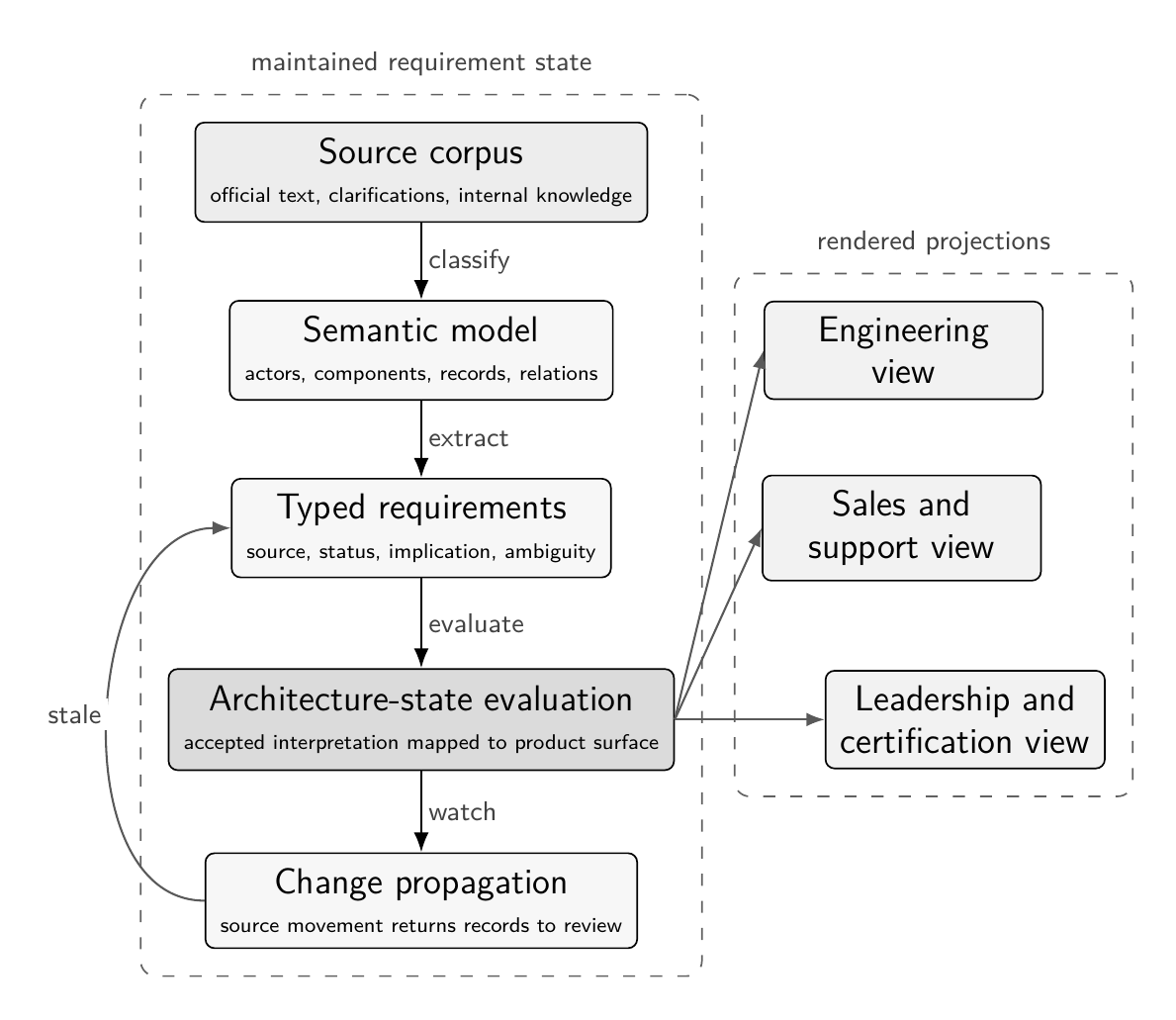
Architecture-state evaluation gates source material before it becomes audience-specific projections.
The statement type determines the review route. A source obligation must return to review when the source changes, a technical rule when the specification changes, and an architectural inference when the product architecture or accepted interpretation changes. An effective requirement taxonomy keeps those review triggers visible beside each requirement.
| Requirement type | Function in the model |
|---|---|
| Explicit regulatory | Preserves obligations stated in official source text |
| Explicit technical | Preserves rules stated in specifications or annexes |
| Derived architectural | Records what follows when source material meets the target architecture |
| Certification-support | Keeps evidence and explanation ready for evaluation |
| Operational | Covers monitoring, onboarding, failure handling, and support |
| Communication | Bounds what sales, support, and partner material can claim |
Requirement taxonomy used to route review triggers.
By this stage, substantial knowledge work has already been done. However, the representation problem does not end once an interpretation has been accepted and enforced at the document level. The team still has to decide where each obligation lands in the architecture, which component owns it, and what evidence proves it. These decisions too need to be sourced, back-linked and maintained.
Text Without State
Distillation usually produces several document types. Each solves a local coordination problem, but each also loses part of the regulatory state when treated in isolation.
| Document type | Useful because | Fails when it stands alone |
|---|---|---|
| Source map | Preserves authority, source version, and relevant passages | Leaves the product decision for another layer |
| Requirement register | Atomises obligations and assigns ownership | Flattens unlike statements unless status and review triggers are typed |
| Architecture note | Records where an accepted interpretation lands in the product | Ages when the architecture changes without a linked review |
| Jira epic or story | Turns an accepted requirement into executable work | Strips source authority and ambiguity down to delivery language |
| Confluence page | Gives teams a readable shared explanation | Relies on manual discipline to keep status, audience, and version true |
| Certification pack | Packages evidence for approval, audit, or institutional review | Optimises for proof and leaves daily product decisions underspecified |
| Sales or support guidance | Translates accepted interpretation into reusable external language | Can detach from authority when edited as ordinary knowledge |
| Open-question log | Keeps ambiguity visible while a decision is pending | Becomes an archive if no owner links it back to the requirement model |
Document projections and the regulatory state they lose when isolated.
These documents are projections from the same product state into different operating contexts. A DMS is a good target for the readable projection, as long explanations, source summaries and cross-team guidance need digestible sources to rely on.
As the product state evolves, the need for a single source of truth emerges quickly. An effective distillation system keeps those properties attached to the same maintained object, then renders the object into the document each team needs. For example, one requirement row can feed a Jira refinement note and a Confluence support page, while both inherit the same source passage and review owner. When that layer is absent, the organisation manages many correct-looking texts, each implying a requirement state. The divergence appears later (and often it is very costly to amend), when an implementation, certification file, sales claim, or support answer no longer matches the regulatory knowledge the product depends on.
Projections From One Model
The projection layer turns the register into working documentation. It renders the accepted product state into targeted audience views while keeping interpretation, source reference, review trigger and owner in one place. A knowledge base (e.g. a collection of Confluence pages) is the readable surface for those views. Each team need ordinary, accessible pages, a dedicated degree of granularity and information density, whereas each page inherits its claims from the maintained model.
The engineering projection converts accepted requirements into buildable work. It shows the atomic requirement, source passage, affected product surface, implementation implication, ambiguity state, refinement links and so forth. A Jira story can then carry both the task and the reason that task exists, so engineering work can return to the model when a source, interpretation, or architecture decision changes.
The sales and support projections translate the same state into permissible language. Sales should receive claims that stay inside the accepted interpretation, while support needs explanations that first map customer vocabulary back to fiscal concepts. A useful output is in plain, understandable but bounded language. Once a sales claim or support answer circulates, customers, partners, or certifiers can treat it as the company’s position, so the projection has to explicitly state its authorisation status.
The leadership projection exposes acceptance state. It groups unresolved interpretations, certification dependencies, risk surfaces, and architecture constraints into a view that shows where the product can proceed and where review remains open. It is less detailed than the engineering register, but its claims need stronger provenance because they guide strategic decisions.
Provenance should be a concrete registry object rather than a tacit and scattered documentation habit. The simplest, most inexpensive solution is a spreadsheet row collecting all relevant requirements attributes (stable requirement ID, source passage ID, interpretation note, linked Confluence or Jira page, owner, status, review trigger etc). Each paragraph, answer or delivery item then references the requirement ID, so the projection carries a pointer to the source and to the decision that licensed it. If such a pointer disappears, source text becomes accepted interpretation, accepted interpretation becomes repeated explanation, and repeated explanations finally collapse in unsupported local claims.
Retrieval Leaves State Unresolved
Retrieval improves access to the corpus. A search index, semantic retrieval layer, or ordinary document query can find the relevant specification paragraph, surface nearby clauses, compare source versions and translate domain terms into comprehensible language. This reduces the cost of reading the corpus and helps teams return to the same shared evidence.
However retrieval is not yet product knowledge. A retrieved paragraph still has to be translated into product state before it can guide implementation or communication. As opposed to treating retrieved material as an accepted answer, we will consider it a candidate product state change, and subject it to review.
A review packet is needed at this point, including retrieved evidence, proposed decision and affected product-state record, as well as a linked owner. The review mechanism itself can be as complex as a full review-routing system, or as simple as a Jira ticket that collects the relevant evidence, records the owner’s decision and keeps the justification in the ticket history.
Change Propagation
We have previously mentioned temporal dimension as a complexity multiplier. Change propagation protects product state current when a source, interpretation, or architecture decision shifts underneath. When one object changes, the model should identify the affected records before teams rediscover the change through implementation work or customer questions.
There are two practical regimes for tackling change propagation. One uses agents to monitor sources, update candidate records, inspect projections, and prepare review packets. The other uses manual operating discipline, with registers, DMS pages, review meetings and so forth.
The agentic version is straightforward in shape. Source changes enter a watcher, changed blocks are matched against requirement IDs, and affected projections are marked for review. The system can draft candidate edits, find unsupported claims, and assemble evidence. The model prepares a state transition, and institutional authority stays with a human owner.
The manual version uses the same state machine, but has, inevitably, weaker enforcement. A spreadsheet can hold source ID, requirement ID, audience, owner, downstream pages, review trigger and status. Confluence can carry the readable view, while review meetings close or reopen tracked assumptions.
At the time I was handling this product, commercial regulatory-change platforms already existed for regulatory-change management.5 They were not, however, widely adopted in my organisation, which preferred custom implementations.
By Q3 and Q4 2025, the agent stack already had APIs with built-in tools and tracing6, coding agents that could edit repositories and run tests7, connector protocols8, and agent builders for orchestration and evaluation.9 The remaining gap was practical reliability for long-horizon knowledge work. Q4 model releases made that gap smaller through stronger tool use10, agentic coding and context management11, while the workflow still needed manual custody over downstream projection control. Operatively, that meant that generated summaries, source excerpts and Confluence drafts had to be manually reconciled against the register before they could become product state.
The operational lesson, resonating even clearer today, is that agentic enforcement should automate the maintenance burden while leaving authority decisions with named owners. The workflow can watch, compare, draft, route and explain. Product owners still decide the accepted interpretation, the allowed projection and what may be said outside the organisation.